Project Vision
Traditional approaches to specialized hardware face fundamental economic barriers: monolithic accelerator designs suffer from prohibitive NRE costs exceeding $500M for 5nm processes, while general-purpose neural network accelerators experience up to 77× energy-delay-product degradation compared to network-specific accelerators. This project develops systematic methodologies for Bespoke Neural Network Accelerators (BNNAs) using chiplet-based architectures that achieve near-monolithic performance while maintaining economic viability.
Our approach establishes a hierarchical co-design framework that simultaneously determines which chiplets should exist and how to optimally arrange them for target applications, fundamentally addressing the chicken-and-egg problem in chiplet-based system design. BNNAs achieve 93.3% of monolithic accelerator performance using just 5-8 strategically selected chiplet types.
Key Research Challenges
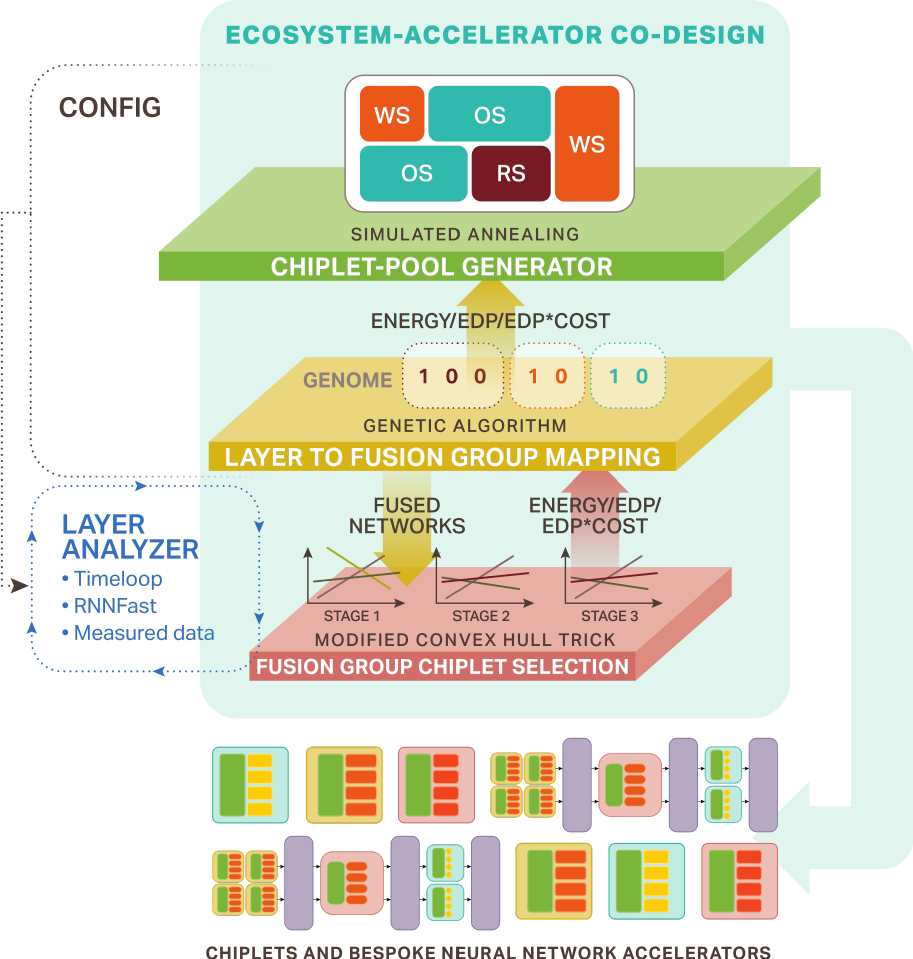
Chiplet Ecosystem Co-Design: Solving the fundamental chicken-and-egg problem of determining which chiplets should be manufactured while designing systems that require knowing what chiplets are available.
Sequential Bottleneck in LLM Decode: Addressing severe underutilization during autoregressive inference where pipeline utilization scales inversely with pipeline depth, limiting effectiveness for the dominant and growing segment of AI workloads.
Tractable Design Space Optimization: Navigating intractably large design spaces for chiplet-based systems while maintaining computational feasibility and near-optimal solutions.
Economic Viability vs. Performance: Balancing specialization benefits against NRE costs to enable practical deployment of application-specific architectures.
Technical Approach
Pipelined Architectural Template: Constrains the intractably large chiplet design space through layer-level hardware customization within pipeline stages, enabling high-throughput execution with multiple parallelization strategies (tensor, data, fusion).
Hierarchical Co-Design Framework: Simultaneously optimizes chiplet pool composition and accelerator configuration using simulated annealing, genetic algorithms, and novel modified convex-hull algorithm that reduces complexity from intractable EXPTIME to manageable O(n).
Adaptive Pipeline Templates: Dynamic reconfiguration between prefill-optimized deep configurations and decode-optimized wide configurations to address LLM autoregressive bottlenecks.
Speculative Decoding Integration: Chiplet-aware implementation using draft models to generate candidate tokens in parallel, transforming sequential decode into partially parallel process.
Expected Outcomes
Core BNNA Framework Performance
- Near-Monolithic Performance: 93.3% of optimal monolithic accelerator performance
- Economic Advantages: 21.3% energy, 10.7% EDP, and 62.6% EDPC improvements over conventional approaches
- Chiplet Efficiency: Strategic use of just 5-8 chiplet types to deliver substantial improvements
LLM Decode Optimization Targets
- Utilization Improvement: >50% utilization improvement for LLM decode phases
- Pipeline Efficiency: >10× utilization improvement over current pipeline approaches
- Model Scalability: Validated performance across 7B to 70B+ parameter models
- Real-time Reconfiguration: Mode switching within microseconds for production deployment
Broader Impact
This research addresses the fundamental inflection point in computing as Moore’s Law scaling ends, establishing systematic methodologies for post-Moore specialization-driven architectures. By solving the economic barriers that prevent widespread adoption of application-specific hardware, BNNAs enable practical deployment of specialized computing across diverse domains.
Beyond AI applications, the techniques for addressing sequential bottlenecks will benefit scientific computing workloads including climate modeling, fluid dynamics, and physical systems simulation. The framework establishes design principles applicable to emerging post-Moore paradigms including chiplet systems, neuromorphic computing, and heterogeneous architectures.
As AI workloads now represent 14% of datacenter power consumption and are projected to reach 27% by 2027, this work directly addresses critical energy efficiency challenges while enabling continued innovation in an era where traditional scaling approaches no longer apply.